Prédire le désabonnement de clients grâce à l’apprentissage machine

Depuis plusieurs années déjà, les entreprises mettent en place des moyens colossaux pour atténuer le désabonnement et maintenir leurs clientèles. Cette problématique est importante dans l’industrie des fournisseurs de service comme Vidéotron, Netflix ou encore Microsoft Office 365.
Rien d’étonnant lorsque l’on sait que plusieurs recherches prouvent qu’il coûte presque 50 fois plus cher d’aller chercher de nouveaux clients que de fidéliser ses clients existants.
Il coûte presque 50 fois plus cher d’aller chercher de nouveaux clients que de fidéliser vos clients existants.
– Financial Post*
Dans cet article nous verrons comment l’apprentissage machine révolutionne la gestion du désabonnement :
- Défi de taille : mesurer le taux de désabonnement
- L’approche traditionnelle BI pour mesurer le désabonnement
- Changement de paradigme grâce à l’apprentissage machine
- Comment appliquer l’apprentissage machine dans votre contexte?

Défi de taille : mesurer le taux de désabonnement
Les entreprises cherchent à mesurer le taux de désabonnement (le fameux churn rate en anglais) afin de pouvoir le réduire par la suite. Évidemment, on ne peut améliorer ce qu’on ne mesure pas. Les approches analytiques et BI traditionnelles utilisent des indicateurs généralisés pour mesurer le désabonnement.
Ces indicateurs présentent de l’information agrégée sur des données passées, par exemple le nombre de désabonnements du mois dernier.
Le problème, c’est que les entreprises utilisant ces techniques sont continuellement dans une approche réactive pour résoudre leur problème de désabonnement. Autrement dit, elles ont toujours un temps de retard.
En regardant le désabonnement de cette façon, on peut par exemple savoir que 25% de nos clients de la cohorte de mai 2018 ont quitté 1 an après. Mais que faire de cette information? Même en faisant des regroupements génériques des raisons du désabonnement sur l’ensemble des clients qui ont quitté, il est très difficile de définir des actions à entreprendre pour résoudre le problème.
La bonne nouvelle c’est que l’apprentissage machine permet maintenant à ces entreprises de développer des modèles prédictifs pour identifier les clients à risque avant qu’ils ne se désabonnent.
Plutôt que d’être réactives, les entreprises ont désormais la chance d’adopter une approche proactive. Il s’agit là d’un véritable changement de paradigme.
Définition : Qu’est-ce que le désabonnement?
Dans le cadre de cet article, nous considérons le désabonnement tout simplement comme étant un client qui annule son contrat de service.
Pourquoi est-il si important de s’intéresser au désabonnement?
Les effets négatifs du désabonnement sont nombreux et nuisent significativement aux entreprises.
1) Augmentation des coûts
Les clients qui tournent le dos aux services d’une entreprise au profit d’un compétiteur leur coûtent très cher. Une fois perdus, il est extrêmement dispendieux de les reconquérir… en plus d’avoir déjà dépensé beaucoup pour les acquérir.
L’acquisition d’un nouveau client coûte généralement 50 fois plus cher que de le fidéliser.
2) La perte de revenus et valorisation de l’entreprise
Une augmentation de seulement 5% du churn rate peut réduire les bénéfices de 25 à 95% et affecter la valorisation de l’entreprise.
3) Le problème du seau percé
La croissance du nombre de clients nets restera stagnante si l’entreprise ne gère pas le churn. Évidemment, perdre le même nombre de clients que le nombre de nouveaux clients n’est pas synonyme de croissance!
Cette phrase peut paraître anodine, cependant, la course à l’acquisition de prospects est souvent la seule préoccupation des départements marketing qui laissent de côté la rétention de clientèle.
4) L’insatisfaction des clients
Si vos clients ne sont pas satisfaits et se désabonnent de vos services, ils ne vont pas vanter l’entreprise dans leur entourage. Ces commentaires auront un impact négatif sur l’image de marque et, à terme, cela fera augmenter significativement vos coûts d’acquisition.
L’approche BI traditionnelle pour mesurer le désabonnement
En général, les entreprises utilisent une approche BI pour mesurer le taux de désabonnement (aussi parfois appelé taux d’attrition).

Le taux de désabonnement est important pour les entreprises puisqu’il est l’indicateur par excellence de la satisfaction de leur clientèle. S’ils sont frustrés et insatisfaits, ils quittent! C’est tout simple.
Bien comprendre ces indicateurs est essentiel pour mesurer les effets des actions marketing : sont-elles bénéfiques? L’entreprise est-elle sur la voie de la rentabilité?
Le cœur du système de mesure de la satisfaction client est le taux de désabonnement.
Personne inconnue et inspirante qui connait bien les enjeux du désabonnement
L’approche BI pour résoudre le désabonnement
Comme mentionné précédemment, l’extrant des approches BI traditionnelle est réactif par définition. Les activités marketing sont donc entreprises APRÈS le churn.
L’image ci-dessous présente les efforts marketing dans une approche BI traditionnelle. La question principale est : « Maintenant que le client s’est désabonné, comment nous pouvons le regagner ? »
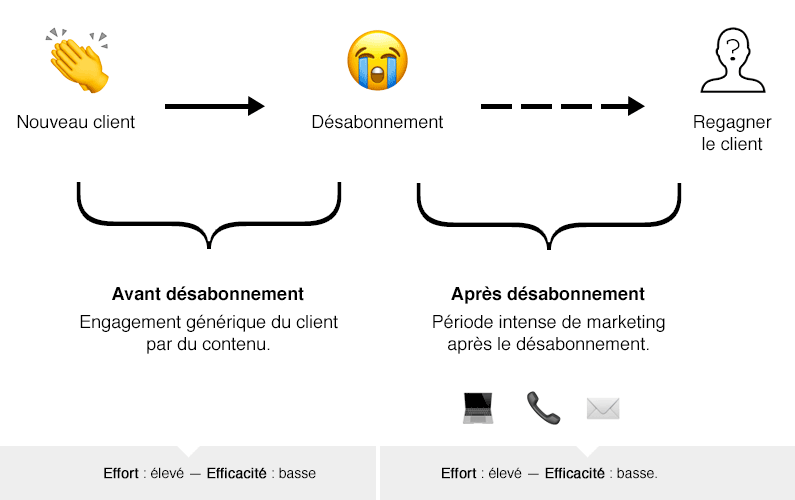
Malgré tout, les stratégies de rétention traditionnelles comportent des éléments permettant aux entreprises d’apprendre de leurs erreurs et tenter de regagner leurs clientèles.
1) Améliorations des services
Certaines entreprises vont s’adresser aux clients désabonnés pour comprendre leur motif et améliorer leurs services en fonction de leurs commentaires.
Un bon exemple : les sondages de satisfaction. Malheureusement, leur taux de participation est généralement très faible :
2) Envoi de promotions agressives post-churn
Une stratégie de rétention largement utilisée consiste à l’envoi de promotions agressives post-désabonnement. Une fois de plus, le taux de conversion de ces offres est très bas.
Nous avons tous été dans cette situation frustrante où une compagnie nous rappelle une fois que nous l’avons quittée avec une offre alléchante. Pourquoi n’avons-nous pas profité de ces rabais AVANT de quitter l’entreprise ?
Certains consommateurs utilisent même cette technique comme technique de négociation. Ça fonctionne parfois, mais le coût pour votre notoriété de marque est immense.
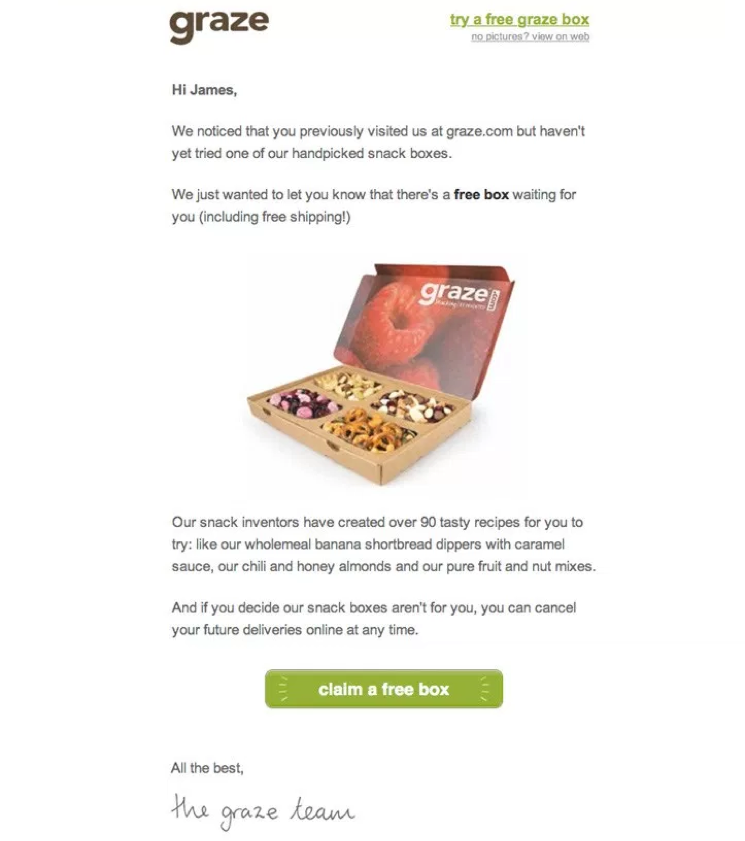
Voici un exemple de courriel de rétention après désabonnement :
Les lacunes de l’approche BI traditinonelle
Les approches BI génèrent certains enjeux.
1) L’enjeu des agrégats
Est-ce que savoir que 12% des clients se désabonnent chaque mois donne de l’information sur les raisons qui expliquent cette tendance? Non! Est-ce que cette mesure donne des pistes d’actions? Non plus!
C’est logique : aucun agrégat ne communiquera le comportement d’un client en particulier. C’est même l’effet inverse, un agrégat est une compression avec une perte d’information. Les agrégats présentent les grandes tendances mais cachent l’information la plus pertinente et actionnable.
2) L’enjeu de la latence
Un autre problème avec les approches BI est que l’indicateur du taux de désabonnement présente uniquement des événements passés.
Dans cette approche, les entreprises seront averties que quelque chose ne va pas, dans le meilleur des cas, le mois suivant le désabonnement de leurs clients… mode réactif plutôt que proactif.
Changement de paradigme grâce à l’apprentissage machine
Imaginez si votre entreprise pouvait intervenir auprès de ses clients à risque, mais AVANT que ceux-ci quittent. Par exemple en offrant du marketing ultra-personnalisé aux clients qui ont le plus de risque de quitter.
C’est exactement ce qu’offre l’apprentissage machine : un système d’alerte proactif pour identifier les clients à risque et leurs motifs particuliers.
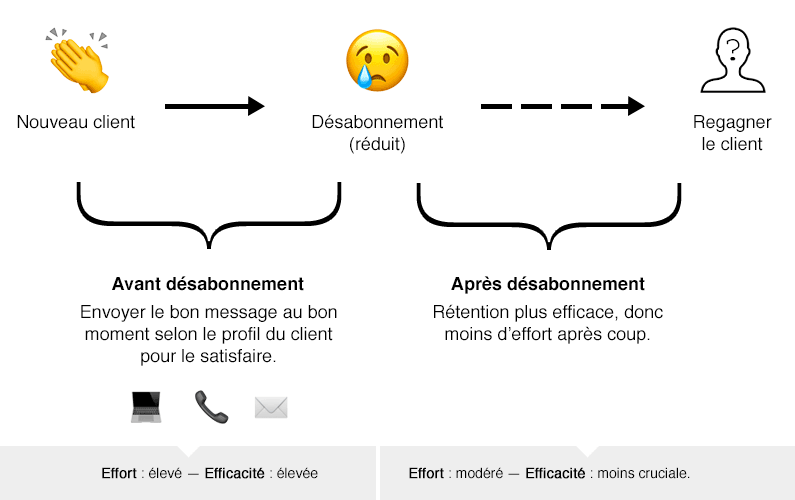
Si vous pouviez comprendre pourquoi certains clients sont à risque, quelles actions entreprendriez-vous pour les conserver?
Les effets positifs :
- Concentrer les efforts, ressources matérielles et financières de rétention sur les clients profitables.
- Réduire les coûts et les pertes.
- Augmenter le nombre de clients tout en réduisant le taux de désabonnement
Comment appliquer l’apprentissage machine pour contrer le désabonnement dans votre contexte.
Indice : grâce aux données!
Vos données constituent la matière première pour alimenter n’importe quel modèle prédictif. En les examinant, vous pourrez identifier les caractéristiques et comportements à facteurs prédictifs du désabonnement de vos clients.
Par exemple, vous pouvez regarder le nombre d’appels de support, les données de consommation, les promotions en cours, le type et la composition des forfaits des clients qui ont résilié leur contrat de service, etc.
En adaptant un modèle statistique selon ces facteurs prédictifs, vous pourrez obtenir la probabilité de désabonnement des clients existants.
En science des données, il s’agit d’une problématique de classification binaire. Les prédictions indiquent la probabilité pour chaque client qu’ils appartiennent ou non à la classe des clients à risque.
Les principales étapes au développement d’un modèle statistique
Sans entrer dans les détails techniques, le développement d’un modèle prédictif suit des étapes bien précises afin d’assurer le succès d’un projet. Voici les étapes et une courte description de chacune d’elles.
1) Définir la problématique et objectif d’affaires
La première étape consiste à définir la problématique d’affaires ainsi que les résultats souhaités. Ce n’est qu’en comprenant l’objectif final que vous pourrez construire un modèle utile. Dans notre cas, il s’agit d’identifier les clients à risque de se désabonner.
2) Collecter les données utiles
Nous devons ensuite identifier les meilleures sources de données, puis les collecter et les agréger. Cela semble assez simple à priori, mais c’est la partie la plus difficile. N’oublions pas qu’un modèle prédictif est toujours aussi bon que la qualité des données utilisées pour le développer. Le fameux, garbage in garbage out.
Je vous conseille donc d’apporter une attention particulière à cette étape afin d’assurer le bon fonctionnement de votre modèle. En général, vos données CRM constituent une bonne première étape.
Elles comprennent, par exemple, les données sociodémographiques, les données d’usage et de consommation, le nombre d’appel aux services clients et techniques, le type de forfait, etc.
3) Nettoyage, sélection et création des variables
La troisième étape consiste à la préparation des données qui alimenteront le modèle prédictif. C’est l’étape la plus chronophage en apprentissage machine.
Il est cependant important de rester concentré et de s’assurer que les données soient propres et prêtes pour entrainer le modèle.
4) La modélisation statistique
Pour obtenir de bonnes prédictions, il faut trouver le bon algorithme et évaluer sa performance. Il existe de très bons algorithmes open source pouvant répondre à votre problématique et à vos données. Sachez que cette étape comporte généralement plusieurs itérations.
Il existe des différences de performance, de rapidité ou encore d’interprétabilité entre les algorithmes.
La règle du 80/20 pour entraîner, tester et valider l’algorithme.
80% des données historiques sont utilisées pour entraîner le modèle statistique.
Le 20% restant est utilisé pour valider si le modèle donne les bons résultats. Ces données de test sont vues comme des données nouvelles puisqu’elles n’ont pas été utilisées dans la phase d’entrainement de l’algorithme.
5) Obtenir les prédictions
Une fois le modèle statistique testé et validé, vous serez en mesure d’identifier vos clients à risques. Un modèle permet non seulement de découvrir ces clients mais également les caractéristiques ayant une influence sur le désabonnement.
Une fois votre modèle développé, il est vivement recommandé de partager ces informations avec votre équipe marketing pour leur permettre d’adapter leur stratégie de rétention.
Dans de nombreux cas, l’équipe de support à la clientèle sera en mesure de fournir des informations qualitatives supplémentaires susceptibles de vous permettre d’optimiser votre modèle et donc la performance des prédictions.
6) Passer à l’action
Une fois que vous avez en main les probabilités que vos clients se désabonnent, vous devez mettre en place des actions concrètes. La meilleure et la plus évidente: contactez-les.
Prédire le désabonnement des clients ne représente que la moitié de la problématique d’affaires : les prédictions ne servent à rien si elles ne sont pas suivies par des actions concrètes.
Examinez leur profil, identifiez leurs caractéristiques, analysez les interactions passées avec vos services et produits. Communiquez vos plus récentes offres et services susceptibles de combler leurs besoins.
Assurez-vous de leur proposer des solutions adaptées à leurs besoins, de ce fait vous créerez un sentiment d’appartenance chez vos clients et cela les liera à votre entreprise.
Car je le répète encore une fois, un algorithme sans action n’a aucune valeur!
Imaginez la force du message pour le client à sa réception :
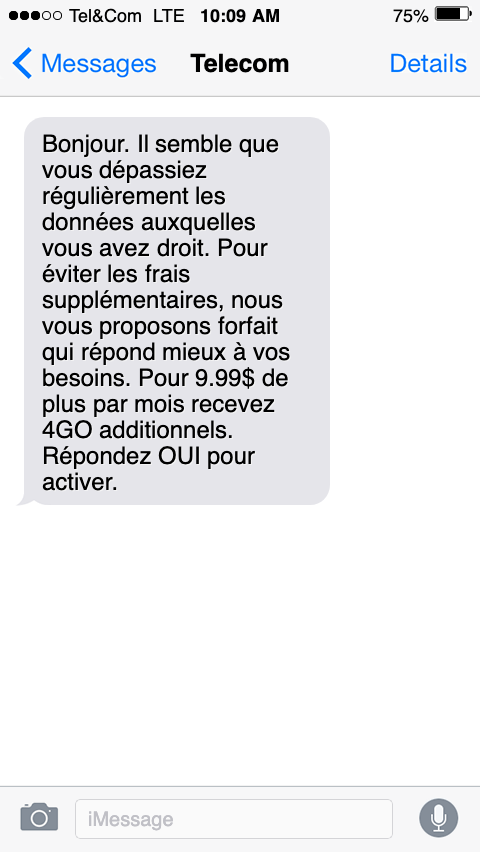
Et un client heureux et bien traité donne des bénéfices à l’entreprise : vente incitative, plus de revenus par mois… et moins de tracas de support client.
Bienvenue dans l’ère du marketing prédictif.
*traduction libre : source.
Simon est un scientifique de données avec un fort background en statistique, science de données, marketing et de recherche utilisateur. Il est passionné à propos des projets qui transforment les données en information qui ont un réel impact sur les décisions d’affaires.
Initiation au Deep Learning avec Google Colab

Le Deep Learning et la science des données, deux sujets à la mode, qui sont sur toutes les langues! Vous aimeriez vous initier, mais ne savez pas comment configurer un environnement de développement Python sur votre ordinateur pour vos premiers projets.
Dans cet article, je vous présenterai les nombreux avantages d’un outil Cloud, simple, gratuit et adapté à la science des données : Google Colaboratory. Cet outil permet de développer des applications en Deep Learning en Python en un éclair. Pour commencer, il vous suffit simplement d’avoir un compte Gmail.
Qu’est-ce que Google Colaboratory et quels en sont les avantages ?
Google Colaboratory ou Colab, un outil Google simple et gratuit pour vous initier au Deep Learning ou collaborer avec vos collègues sur des projets en science des données.
Colab permet :
- D’améliorer vos compétences de codage en langage de programmation Python.
- De développer des applications en Deep Learning en utilisant des bibliothèques Python populaires telles que Keras, TensorFlow, PyTorch et OpenCV.
- D’utiliser un environnement de développement (Jupyter Notebook) qui ne nécessite aucune configuration.
Mais la fonctionnalité qui distingue Colab des autres services est l’accès à un processeur graphique GPU, totalement gratuitement! Des informations détaillées sur le service sont disponibles sur la page FAQ de Colab.
Comme son nom l’indique, Google Colaboratory s’accompagne du terme « collaboration ». En fait, Colab exploite les mêmes fonctionnalités de collaboration des autres éléments de la G Suite : Sheet, Slide, Docs, etc. Il fonctionne sur les serveurs Google et vous n’avez rien à installer.
De plus, les documents Colab (Jupyter Notebook) sont enregistrés directement votre compte Google Drive.
Guide pas à pas pour activer Google Colab et développer votre premier modèle en Deep Learning
Étape 1 – Créer un nouveau dossier sur Google Drive
Dans un premier temps, connectez-vous à votre compte Gmail (ou G Suite) puis rendez-vous dans l’application Google Drive et créez un nouveau dossier. Dans cet exemple, j’ai créé un dossier nommé « app » dans mon Google Drive. Vous pouvez bien sûr utiliser un nom différent.
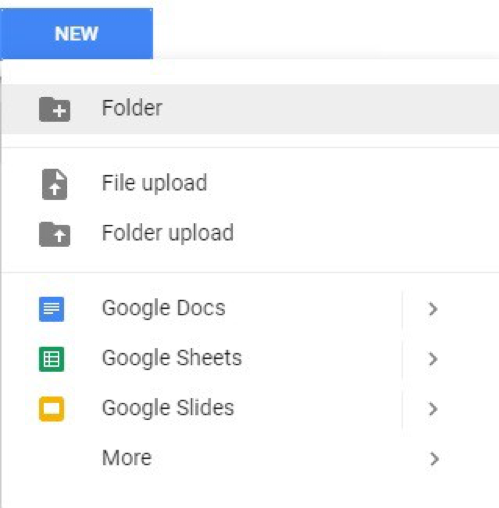
Une fois le dossier créé, vous devriez obtenir un écran similaire à celui-ci :
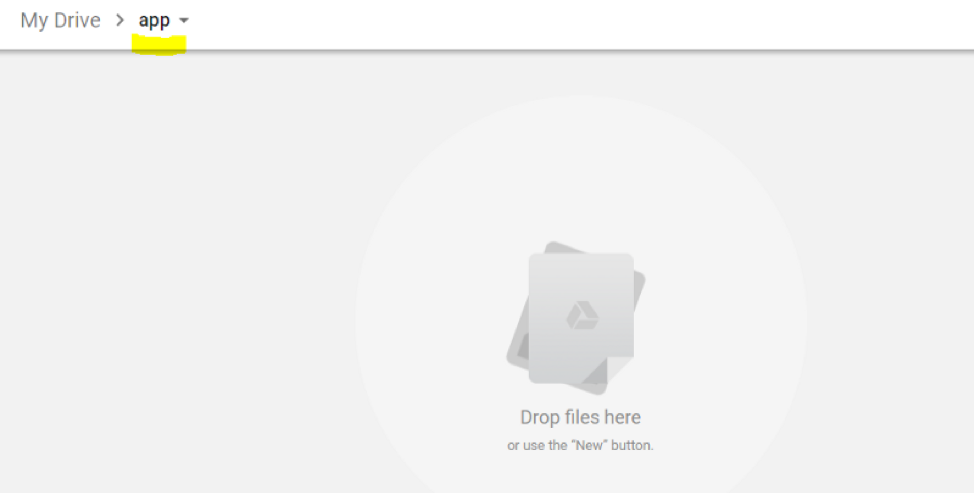
Étape 2 : Créer un nouveau fichier Colab
Dans votre nouveau dossier, faites un clic droit avec votre souris puis sélectionnez More > Colaboratory.
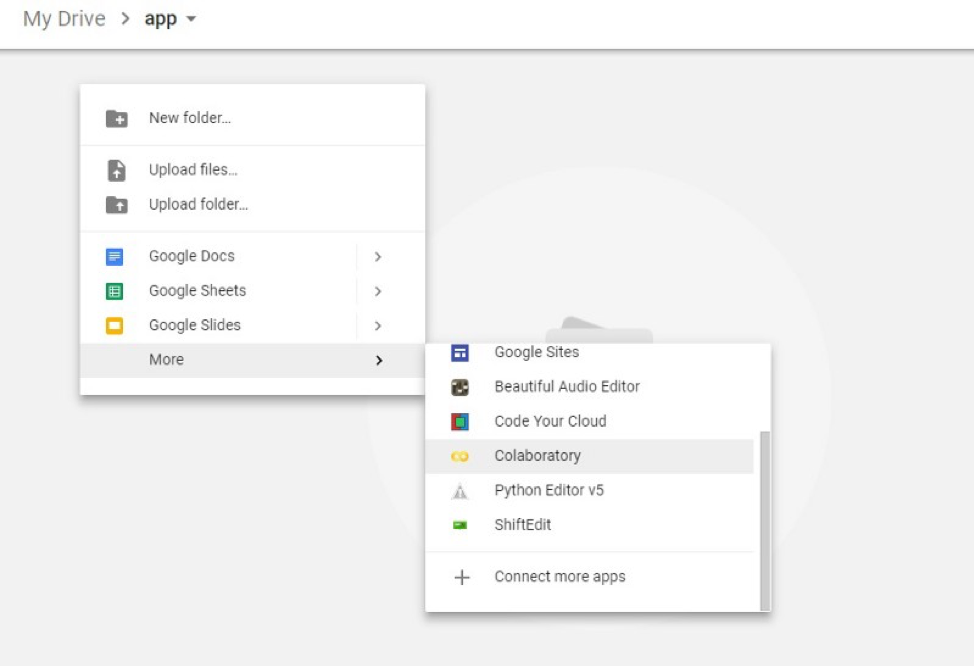
Une fois dans le nouveau fichier, vous pouvez le renommer en cliquant sur le nom en haut du document.
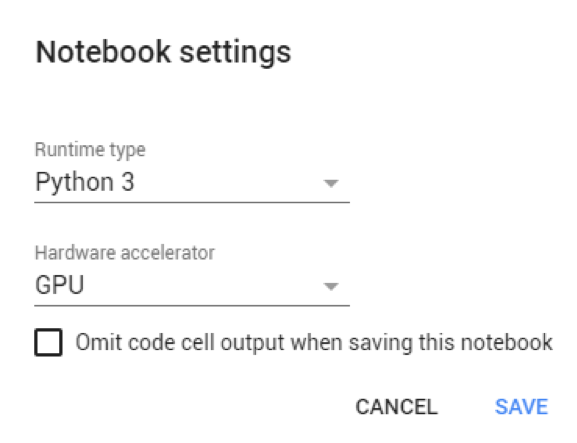
Étape 3 : Paramétrage du GPU gratuit (!)
Pour configurer le GPU (processeur graphique), il suffit de cliquer sur Edit > Notebook settings et sélectionner GPU comme accélérateur matériel.
Étape 4 : Exécuter du code Python de base
Nous pouvons dès maintenant commencer à utiliser Colab.
À titre d’exemple, je vais exécuter quelques lignes de code du tutoriel Python Numpy. Numpy est une librairie Python populaire en science des données utilisée pour des calculs mathématiques.
Si vous ne connaissez pas encore Python, c’est le langage de programmation le plus populaire en Intelligence Artificielle. Pour vous initier à Python je vous recommande ce tutoriel simple.

Ça fonctionne comme prévu 🙂! Pour exécuter le code, il suffit de cliquer sur le bouton play à gauche de la ligne de code.
Étape 5 : Votre premier modèle en Deep Learning
Voici un script qui vous permettra d’entraîner votre premier modèle en Deep Learning, vous avez simplement à copier/coller le code suivant et apprécier le travail de la machine.
'''
Train a simple convnet on the MNIST dataset.
(there is still a lot of margin for parameter tuning).
'''
from __future__ import print_function
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras import backend as K
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.losses import categorical_crossentropy
from tensorflow.keras.optimizers import Adadelta
batch_size = 128
num_classes = 10
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, split between train and test sets
# if you have an error loading data in your IDE, try the following link:
# https://github.com/tensorflow/tensorflow/issues/33285
(x_train, y_train), (x_test, y_test) = mnist.load_data()
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=categorical_crossentropy,
optimizer=Adadelta(),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
Si tout se passe bien, voici ce que vous devriez voir :

Si c’est le cas, félicitations, vous venez d’entraîner votre premier modèle en Deep Learning dans Colab sans même vous en rendre compte! Si ce n’est pas le cas, je vous invite à nous écrire dans les commentaires.
Maintenant que vous avez à votre disposition un environnement de développement Python, vous avez l’essentiel pour commencer votre apprentissage du Deep Learning.
Je vous conseille de suivre ce tutoriel complet pour vous aider à télécharger vos ensembles de données dans Colab et cet autre tutoriel pour vous initier aux bases de la science des données grâce à la populaire librairie Scikit-Learn.
Google Colab pour démocratiser l’intelligence artificielle
Finalement, je pense que Colab permet vraiment de démocratiser l’accès à l’Intelligence Artificielle . C’est un outil aussi simple à utiliser que performant. Ses avantages sont très nombreux.
Et que dire de l’accès gratuit à un GPU!
En espérant que cet article vous soit utile, n’hésitez pas à laisser un commentaire ci-dessous.
Simon est un scientifique de données avec un fort background en statistique, science de données, marketing et de recherche utilisateur. Il est passionné à propos des projets qui transforment les données en information qui ont un réel impact sur les décisions d’affaires.



