
L’objectif de ce guide est de vous fournir toute l’information pertinente afin de bien comprendre ce qu’est l’OCR, quels sont ses avantages et comment en tirer profit dans un contexte d’affaires.
Qu’est-ce que la reconnaissance optique de caractères?
La reconnaissance optique des caractères, ou Optical Character Recognition – OCR en anglais, est une conversion électronique d’images textuelles dactylographiées, manuscrites ou imprimées. Ce texte est encodé par une machine dans un fichier de format texte.
Avec l’OCR, un grand nombre de documents papier peuvent être numérisés en texte lisible à la machine, peu importe la langue et le format dans lesquels ils sont rédigés. Cette technique facilite non seulement le stockage, mais rend disponibles des données qui auparavant étaient difficilement accessibles.
Il suffit simplement de penser à la quantité de données qui dorment dans des boîtes d’archives papier d’une ville ou d’un gouvernement par exemple.
Ces images et documents peuvent être numérisés sous forme de document texte, de photo de document ou de photo de scène (par exemple pour décoder le texte sur un panneau d’affichage).
Comment fonctionne l’OCR?
Le challenge de l’OCR repose principalement sur la difficulté à reconnaître les différentes polices de caractères qui démultiplient les façons d’écrire chaque symbole. Ceci fait en sorte qu’avant même de sélectionner un algorithme d’OCR, l’image en elle-même doit être prétraitée pour en assurer la lecture.
Prétraitement
La majorité des logiciels d’OCR prétraitent les images pour augmenter les chances de reconnaissance.
Les techniques de prétraitement comprennent :
1. Réalignement (de-skew)
Si le document n’a pas été correctement aligné lorsqu’il est numérisé, il peut avoir besoin d’être tourné de quelques degrés dans le sens horaire ou antihoraire pour s’assurer que les lignes de texte soient parfaitement horizontales ou verticales.
2. Déparasitage (Despeckle)
Enlever les taches sur le document ou lisser ses bords.
3. Binarisation
Convertir une image en noir et blanc (appelé une « image binaire » parce qu’il n’y a que deux couleurs). La tâche de binarisation est effectuée comme un moyen facile et précis de distinguer le texte de l’arrière-plan.
4. Suppression de la ligne
Nettoyer les boîtes et les lignes non glyphes.
5. Analyse de mise en page ou « zonage »
Identifier les colonnes, les paragraphes, les légendes, sous forme de blocs. Particulièrement utile dans les mises en page et les tables multicolonnes.
6. Détection de lignes et de mots
Établir des formes avec les mots et les caractères de base, diviser les mots au besoin.
7. Reconnaissance du script
Dans plusieurs documents linguistiques, le script peut se transformer au niveau des mots. Donc l’identification du script est essentielle avant que l’OCR puisse être utilisé pour gérer un script en particulier.
8. Isolation des caractères ou « segmentation »
Divers caractères liés par des artefacts d’images doivent être divisés. Par exemple, les caractères uniques qui ont été divisés en plusieurs morceaux basés devraient être liés.
9. Normalisation
Normaliser le ratio des dimensions de l’image (aspect ratio) et l’échelle (scale ratio).
Extraction des propriétés statistiques de l’image
Il existe essentiellement deux méthodes principales pour extraire les propriétés statistiques d’une image en OCR :
- l’algorithme de détection définit un caractère en évaluant ses lignes et ses traits;
- la reconnaissance des motifs, fonctionne en identifiant l’ensemble du caractère.
Nous pouvons reconnaître une ligne de texte en recherchant des lignes de pixels blancs qui ont des pixels noirs entre les deux. De la même façon, nous pouvons reconnaître où un caractère commence et où il se termine.
Les images suivantes démontrent visuellement ces méthodes respectivement :


Ensuite, nous convertissons l’image du caractère en une matrice binaire où les pixels blancs sont des 0 et les pixels noirs sont des 1 comme indiqué dans l’image suivante :

Par la suite, en utilisant la formule de distance, nous trouvons la distance du centre de la matrice jusqu’au 1 le plus éloigné.
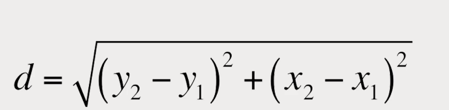
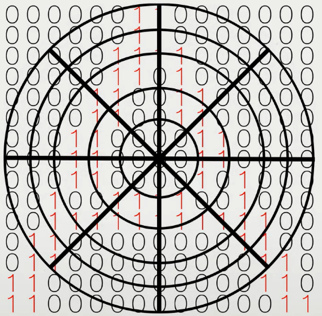
Nous créons ensuite un cercle en utilisant la distance comme rayon et le divisons en sections plus granulaires.
À ce stade, l’algorithme compare chaque sous-section à une base de données de matrices représentant des caractères dans différentes polices pour identifier le caractère avec lequel il a le plus de similarités statistiques. Pour numériser un média imprimé, l’algorithme reproduit cette technique pour chaque ligne et caractère.
Post-traitement
La précision de l’OCR peut être améliorée si son extrant est limité par un lexique (une liste de mots autorisés dans un document). Par exemple, un lexique pourrait comprendre tous les mots en anglais ou une liste de mots plus techniques spécifiques à un domaine en particulier.
Évidemment, cette méthode sera moins efficace si le document contient des mots qui ne sont pas dans le lexique. C’est souvent le cas avec les noms propres par exemple.
Heureusement, pour améliorer la précision il existe plusieurs librairies d’OCR gratuites sur Internet. La librairie Tesseract par exemple utilise son dictionnaire pour contrôler la segmentation des caractères.
L’extrant de l’algorithme peut être une seule chaîne ou un fichier de caractère. Les systèmes OCR plus avancés peuvent conserver la structure de page d’origine et créer un PDF contenant à la fois les pages d’image d’origine et le rendu textuel décodé.
Corriger les erreurs
Afin de corriger certaines erreurs, l’analyse des proches voisins peut utiliser des fréquences de cooccurrence en notant que certains mots ont été vus ensemble. Par exemple de ces deux expressions similaires, « Washington, D.C. » est plus répandu dans la langue anglaise que « Washington DOC ».
La grammaire
La grammaire peut également aider à déterminer la langue numérisée, par exemple, un mot est susceptible d’être un verbe ou un nom, fournit une plus grande précision.
Dans le post-traitement OCR, l’algorithme de distance de Levenshtein est souvent utilisé pour maximiser davantage les résultats de l’OCR.
Cas d’utilisation de l’OCR
Les outils d’OCR ont été développés en une gamme d’applications spécifiques au domaine, notamment la reconnaissance de reçu, de facture, de chèques, de documents légaux, etc.
D’autres cas d’utilisation peuvent être :
- Saisie automatique de données pour des documents d’entreprise, par exemple : formulaires papier, chèques, passeports, factures, relevés bancaires, reçus, etc ;
- Reconnaissance automatique des plaques d’immatriculation ;
- Reconnaissance des passeports de voyageurs dans un aéroport et l’extraction de l’information importante ;
- Extraction automatique d’informations clés dans des documents d’assurance ;
- Extraction des informations de carte d’affaires ;
- Numérisation de gros documents imprimés, par exemple des livres ;
- Rendre disponible à la recherche le texte d’images des documents imprimés ;
- Conversion de l’écriture manuscrite en temps réel pour contrôler un ordinateur (pen computing – via une tablette graphique ou un écran tactile par exemple).
Les domaines où l’OCR est le plus utilisé
Domaine bancaire, assurances et valeurs mobilières.
Ces 3 secteurs, de par leur nature, sont tous de grands consommateurs de l’OCR.
L’utilisation la plus courante de l’OCR est la saine gestion des chèques :
- le chèque manuscrit est numérisé ;
- ses détails sont transformés en texte numérique ;
- la signature est validée ;
- le chèque est approuvé en temps réel.
Le tout sans implication humaine.
Aujourd’hui, seule la vérification de la signature nécessite la validation avec une valeur résidente dans une base de données préexistante.
Caractères manuscrits
Malgré tout, nous sommes plutôt loin de l’automatisation complète de la validation de caractères manuscrits comme la façon d’écrire de chaque personne est presque unique.
Par contre, l’application de méthodes d’apprentissage profond (deep learning) appliquées à l’écriture OCR nous permet d’être optimistes d’espérer automatiser à 100% le traitement des chèques.
Une diminution du temps de traitement des chèques est un avantage financier pour tout le monde : le débiteur, la banque et le créditeur.

Monde légal
Peu d’industries génèrent autant de paperasse que l’industrie juridique, donc il est simple de comprendre les avantages de l’OCR ici.
La numérisation, le stockage, la conservation en base de données accessible à la recherche sont désormais possibles pour tous les documents imprimés : affidavits, jugements, déclarations, avis, testaments, etc.
L’OCR est également disponible pour des documents en chinois, en arabe et en orthographes pour les langues ayant une autre écriture que celles de type « romaine ».
L’accès rapide aux documents juridiques provenant de millions de cas antérieurs est certainement un avantage pour une industrie qui s’appuie fortement sur un le passé.
Santé
Une autre industrie qui se prête bien à l’OCR est la santé. Il est possible de numériser tout l’historique médical d’un patient : rapports de santé, radiographies, historique de maladies, suivi des traitements, diagnostics, dossiers hospitaliers, couverture d’assurance, paiements. Après numérisation, toutes ces informations sont disponibles et consultables en un seul endroit.
Le fait que l’ensemble du dossier patient soit stocké numériquement représente un avantage majeur pour l’épidémiologie et pour la logistique (maintien des niveaux de médicaments en pharmacies, équipements et autres produits de santé, etc.)
Une fois numérisés, tous les dossiers forment une énorme base de données qui peut être utile d’étudier dans son ensemble pour fournir des insights aux législateurs et aux réseaux de santé partout dans le monde.

Chaîne d’approvisionnement
Dans plusieurs secteurs, le contrôle de la qualité de la chaîne d’approvisionnement à chaque étape du processus est essentiel pour se conformer, entre autres, aux lois de sécurité, santé et de lutte contre la contrefaçon.
Certains articles doivent être localisés dans la chaîne d’approvisionnement à tout moment, et fournir une documentation claire de leur origine et de leur emplacement.
Bien que le suivi des produits soit souvent géré grâce aux code-barres ou aux puces de type « Near Field Communication (NFC) », l’OCR a malgré tout une utilité.
Il permet de lire les instantanément codes des lots, les dates d’expiration et les numéros de série. Ces informations améliorent le suivi d’un produit à toutes les étapes du cycle d’emballage, de l’étiquetage à la mise du produit final sur les tablettes.
L’OCR peut être également utile pour comparer le texte actuel avec la chaîne prévue définie dans la base de données, et signaler un numéro de série hors séquence ou manquant.
Les code-barres et l’OCR sont souvent utilisés de pairs pour maximiser l’exactitude de la collecte d’informations.

Avantages de l’OCR
Facilité de recherche
Vous pouvez enregistrer votre fichier numérisé sous la forme de .doc, .rtf, .txt, pdf, etc., après avoir converti votre fichier numérisé en texte lisible. Vous pouvez facilement mettre ces fichiers à la disposition en les incluant dans une base de données appropriée.
Modification
Vous pouvez facilement apporter des modifications à un vieux contrat que vous aviez rédigé il y a quelques années ou réviser un vieux testament sans passer des heures à retaper manuellement. Après la numérisation de votre document à l’aide de l’OCR, vous pouvez facilement le modifier avec n’importe quel outil de traitement de texte.
Accessibilité
Une fois qu’un document numérisé est rendu accessible sur une base de données commune, il devient instantanément accessible à plusieurs personnes. Ceci est particulièrement utile pour les banques qui peuvent vérifier les antécédents de crédit d’un client en tout temps.
Cette technique permet de rendre les archives gouvernementales disponibles afin que les archives des propriétaires d’entreprises ou l’acte de naissance du grand-père du client d’un avocat puissent être trouvés par une simple recherche textuelle.
Stockage
La numérisation réduit évidemment l’espace nécessaire pour le stockage des archives papier, comme les ordinateurs ne prennent que peu d’espace physique. De plus, ces dernières, une fois numérisées, deviennent inutiles et peuvent être recyclées.
Sauvegardes
Au lieu de garder des documents en double ou en triple, la numérisation peut être faite à bon marché et sans limites. On peut également conserver une version de tous les changements. De plus, les documents numérisés ne risquent pas de s’abimer avec le temps.
Ça simplifie de beaucoup la gestion documentaire.
Traduisibilité
L’OCR moderne est capable de gérer un grand nombre de langues, de l’arabe à l’indien en passant par le chinois. Cela implique qu’un document, dans une langue, peut être recherché, numérisé et automatiquement traduit dans n’importe quelle autre langue.
Ce travail est de beaucoup simplifié avec la norme Unicode et les programmes de traduction basés sur l’apprentissage machine (par exemple, Google Translate).
Par conséquent, nous pouvons presque éliminer le besoin de recourir à des traducteurs professionnels.
Comment l’OCR aidera votre entreprise?
L’OCR présente plusieurs avantages. De nos jours, les entreprises génèrent souvent un volume très élevé de données et de documents : contrats légaux, bordereau d’expédition, formulaires gouvernementaux, licences d’utilisation, certificats, catalogues, etc.
Grâce à l’OCR et à la numérisation, en plus de l’archivage numérique, la comparaison entre les documents est possible et beaucoup plus simple.
Vous pouvez vérifier les écarts et informations contradictoires dans vos systèmes. Par exemple, les chèques peuvent être vérifiés pour valider le bon montant et les factures peuvent être comparées aux comptes à recevoir et aux paiements reçus, etc.
Finalement, en numérisant vos documents, vous les rendez disponibles pour fins d’analyse statistique. Cette activité peut vous donner très rapidement des pistes d’amélioration pour les processus pour votre entreprise.
L’OCR est la première phase critique de la transformation des enregistrements analogiques en documents numérique.
Si vous voulez en savoir plus, quelques références et documents (en anglais) intéressants sur le sujet :

Guillaume est cofondateur de Moov AI et expert en marketing numérique.
Directeur marketing pour Urban Turtle (Pyxis Technologies) et Sharegate (GSoft), il a participé à la gestion des stratégies pour des produits ayant un fort succès commercial.





