
La rapide croissance des performances des outils utilisant l’intelligence artificielle (IA) soulève plusieurs questionnements et inquiétudes.
Malgré que ces technologies soient présentées comme infaillibles, sommes-nous prêts à les inclure dans des infrastructures critiques? Pensons par exemple à des systèmes prenant des décisions de manière autonome pour la santé ou la sécurité des citoyens.
Qu’arriverait-il si un acteur malveillant réussissait à tromper un algorithme à son avantage? Comment est-il même possible de réussir un tel exploit?
Est-il possible, à priori, d’identifier les points faibles d’un algorithme afin de le rendre plus robuste face à des attaques?
Ce type de questionnement est à l’origine de l’émergence d’un domaine de recherche en informatique : la génération d’adversarial examples (ou exemples contradictoires en français).
À qui s’adresse cet article?
Quiconque intéressé par l’apprentissage machine ou l’IA devrait être informé de l’existence de ce phénomène, ne serait-ce que pour comprendre les limites applicatives de ce type de technologie.
L’article est plutôt technique, mais j’ai vulgarisé afin de rendre le sujet le plus digeste possible, même pour les gens un peu moins techniques. Vous y trouverez :
- Que sont les adversarial examples et à quoi ressemblent-ils?
- Terminologie associée aux adversarial examples
- Comment pourraient-ils affecter notre vie au quotidien?
- Comment ces exemples peuvent être générés?
- Comment mesurer la robustesse d’un algorithme à ce type d’attaque?
Qu’est-ce qu’un adversarial example?
L’équipe de Machine Learning à l’Université Berkeley décrit les adversarial examples « comme étant des illusions optiques pour les machines. » Ce sont des données trompeuses, qui déjouent un l’algorithme en lui faisant croire quelque chose qui n’est pas vrai.
Dans le contexte d’algorithme de classification, un adversarial example représente un ensemble de données synthétiques, soigneusement élaboré pour induire une mauvaise classification.
Ces données entrées malicieusement sont la combinaison de données initialement correctement classifiées, auxquelles est ajoutée une perturbation pratiquement imperceptible. C’est donc très difficile, pour un œil humain, de discerner si un adversarial example s’est glissé dans son ensemble de données.
Cas concrets d’adversarial example
Regardons quelques images qui ont réussi à tromper le fameux classificateur d’image GoogLeNet, le réseau de neurones de 22 couches développé par des chercheurs de Google.
N.B. Si vous voulez créer votre premier propre réseau de neurones, vous pouvez le faire grâce à l’accompagnement pas à pas de Simon Prud’homme dans cet article.
Il est remarquable que ces exemples soient faussement catégorisés, mais avec une grande confiance! L’algorithme est con-vain-cu qu’il reconnaît le contenu de l’image et qu’il la classifie correctement.
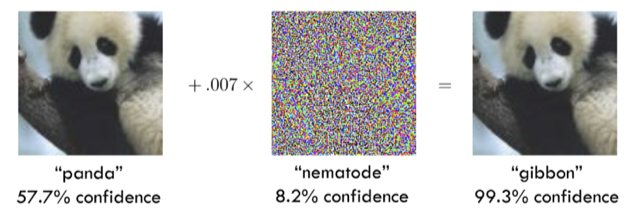
En introduisant une perturbation imperceptible à l’œil nu, Ian Goodfellow et ses collègues ont réussi à faire croire à un algorithme de classification qu’une image contenait un singe gibbon, alors que très clairement cette image représente un panda.
Pour ceux comme moi qui seraient peu familiers avec le « singe gibbon », voici à quoi cela ressemble. On va se le dire, on est loin d’un panda…

Vous pouvez trouver une architecture et le modèle préentrainé via Keras.
Des adversarial examples peuvent également être générés sur des formats de données autres que des images: données tabulaires, séries chronologiques, données textuelles (dans le contexte de traitement du langage naturel, «NLP») et même pour des fichiers audio.
Exemple : algorithme de classification basé sur des séries chronologiques.
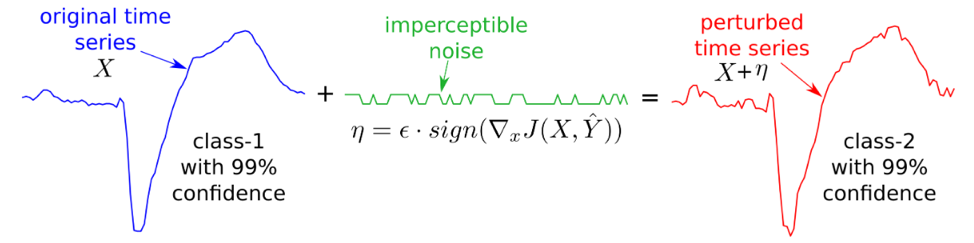
La série en bleu est correctement catégorisée dans une certaine catégorie (la classe 1) alors qu’après l’ajout d’un bruit quasi-imperceptible (en vert), l’algorithme catégorise maintenant l’exemple perturbé (en rouge) dans la classe 2.
Cet exemple pourrait représenter un classificateur qui étudie les électrocardiogrammes de patients d’un hôpital.
Un acteur malveillant pourrait donc induire une perturbation faisant passer la classification de « patient à risque de faire une crise cardiaque » à « patient en santé » … Tiré de : https://arxiv.org/abs/1903.07054
Exemple basé sur des fichiers textes

Ils peuvent être créés soit en supprimant, interchangeant, remplaçant ou insérant des caractères supplémentaires. Habituellement, la sémantique et le sens des phrases reste inchangés.
Dans cet exemple, quelques substitutions et insertion on suffit pour induire en erreur le classificateur de AWS qui est maintenant convaincu que le texte lui étant présenté possède une connotation positive. Voir ici et ici pour plus d’info
Terminologie associée aux adversarial examples
Puisque vous connaissez maintenant le fondement des adversarial examples, vous allez assurément vouloir en discuter, ou même… impressionner votre entourage. Pour ne pas être pris au dépourvu si vous tombez sur un fin connaisseur, voici quelques termes du jargon à connaître.
Attaques d’évasion
La plupart des attaques pour générer des perturbations menant à des adversarial examples se classe dans la catégorie des attaques d’évasion. Ces attaques surviennent lors de la phase d’opération de l’algorithme.
Un attaquant essaie habituellement de dissimuler du contenu malicieux pour permettre à ces échantillons d’être malgré tout catégorisés comme étant légitime. Par exemple, un attaquant pourrait vouloir déjouer un filtre antipourriel.
Ainsi, en ajoutant judicieusement de faibles modifications à son pourriel, il pourrait maintenant être catégorisé comme étant un courriel légitime par le filtre.
L’attaquant n’a donc pas besoin d’avoir accès à l’algorithme durant sa phase d’entraînement.
Attaques d’empoisonnement
Il existe également des attaques d’empoisonnement. Ces attaques sont exécutées lors de la phase d’entraînement initiale ou lors des phases de réentraînement basé sur les données recueillies en opération.
L’objectif est de contaminer les données d’entraînement en injectant graduellement des exemples pouvant compromettre le processus d’apprentissage de la machine. Ainsi, lentement mais surement, l’algorithme base son apprentissage sur de mauvais exemples, au profit de l’attaquant.
Attaques non-ciblées / ciblées
Attaque non ciblée
Une attaque non-ciblée est simplement d’induire une mauvaise classification, peu importe la classe finale déterminée par l’algorithme. Tout ce qui importe, est que la catégorie choisie par l’algorithme ne soit pas la bonne catégorie.
La bonne catégorie est celle choisie lorsque les données non-perturbées lui sont présentées.
Attaque ciblée
Pour une attaque ciblée, l’attaquant désire que la mauvaise classification soit faite dans une catégorie en particulier.
Par exemple, une attaque pourrait permettre à un classificateur reconnaissant des nombres écrits à la main de catégoriser un chèque d’une valeur de 1 000 000$ comme étant un chèque de 9 999 999$…
La catégorie « chiffre neuf » serait donc la catégorie ciblée pour la catégorisation de chaque chiffre. Dans ce scénario, l’attaquant a décidément avantage à cibler une catégorie! 💸 💸 💸

Aucun canard n’a été blessé lors de la rédaction de cet article.
Quantité d’information nécessaire
Les attaques sont également classées selon la quantité d’informations nécessaires à propos de l’algorithme afin de les exécuter.
Attaque boîte noire (Black Box Attack)
L’attaquant n’a besoin d’aucune information sur l’algorithme. Il a simplement besoin d’être capable de lui fournir des données et d’observer la classification résultante.
Attaque boîte grise (Gray Box Attack)
Seulement quelques informations sont nécessaires. Exemple : les catégories possibles et les probabilités de chaque catégorie lorsque l’algorithme effectue une prédiction.
Attaque boîte blanche (White Box Attack)
L’attaquant doit connaître l’intégralité du modèle: son architecture, son processus d’apprentissage, etc. Seul un acteur sachant tous les secrets de l’algorithme peut performer ce type d’attaque.
Les impacts possibles des adversarial examples au quotidien
Adversarial examples et la voiture autonome
Projetons-nous dans un monde, pas si lointain, dans lequel des voitures autonomes sillonnent les rues des grandes métropoles. Afin de se guider et d’amener ses passagers à destination, ces voitures doivent être en mesure de reconnaitre les panneaux de signalisation routière.
Grâce aux algorithmes de reconnaissance de formes et d’images actuellement disponibles, nous sommes passés de la fiction à la réalité dans ce domaine. Cependant, qu’arrive-t-il si un acteur malveillant place un autocollant sur un panneau de signalisation afin de performer une attaque de type évasion ciblée?
La voiture autonome exécuterait donc une mauvaise classification, devenant ainsi un danger public.

Simplement avec un petit autocollant ajouté au bas du panneau d’arrêt, un algorithme de reconnaissance de signalisation routière est convaincu à 97% qu’il voit un panneau de limite de vitesse. Tiré de https://arxiv.org/pdf/1708.06733.pdf.
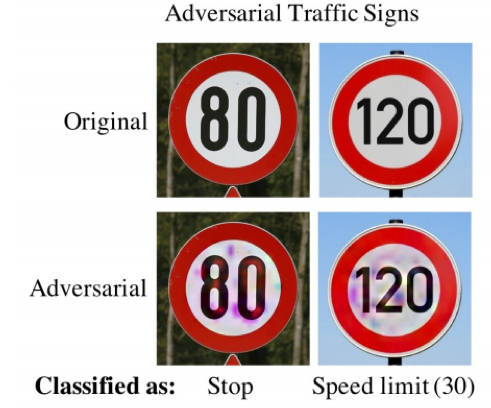
Malgré que les exemples contradictoires puissent sembler anodins à l’œil nu, ils peuvent être dévastateurs auprès des algorithmes de classification. Imaginez une voiture circulant à 30 km/h sur une voie express ou la réelle limite est de 120 km/h… ou l’inverse! Tiré de https://arxiv.org/pdf/1802.06430.pdf.
Adversarial examples et la reconnaissance faciale
Pire encore : on sonne à votre porte, un policier vous demande de le suivre au poste de police.
On vous explique qu’en analysant des séquences vidéo prises par les caméras de surveillance de l’épicerie du coin, un algorithme de reconnaissance faciale a déterminé que vous aviez commis un vol à l’étalage.
Vous êtes outré et essayez de convaincre l’agent que ce n’était pas vous. Rien à faire, vous avez été identifié par l’algorithme comme étant l’auteur du crime.
Voici comment les événements se sont réellement déroulés : une personne a réussi « voler » votre visage uniquement en portant des lunettes qui ont introduit une perturbation dans l’algorithme de reconnaissance faciale.
Que cette attaque soit ciblée ou non, le réel criminel est toujours au large et le blâme est tombé sur vous! C’est du vol d’identité du futur.

Ci-haut, un exemple concret de personnification résultant de l’exploitation d’un adversarial example.
À gauche, une photo de l’actrice Reese Witherspoon correctement classée par un algorithme. Au centre, la même photo, mais incluant une perturbation (les lunettes). Cette photo du centre est maintenant catégorisée par l’algorithme comme étant l’acteur Russel Crowe (à droite).

Dans l’exemple du voleur à l’étalage, ce type de lunette physique pourrait être utilisé pour induire de mauvaise classification de la part d’un algorithme. Tiré de : https://www.cs.cmu.edu/~sbhagava/papers/face-rec-ccs16.pdf.
Je suis conscient que mon exemple de vol d’identité est un peu tiré par les cheveux… Heureusement vous n’avez tout de même pas trop à vous inquiéter puisque ces deux scénarios sont basés sur des attaques de type « boîte blanche ».
Il est donc très peu probable qu’un acteur externe soit capable de réaliser les deux exemples physiques présentés sans une connaissance approfondie du modèle.
En revanche, la bonne nouvelle est qu’il est possible d’utiliser à bon escient les attaques de type boite blanche pour valider la robustesse d’algorithmes de classification.
Comment générer des adversarial examples?
Les adversarial examples existent, car la frontière de décision d’un algorithme ne représente pas parfaitement la frontière réelle pour une tâche de classification.
Il est donc possible, en connaissant le processus d’apprentissage de l’algorithme ainsi que ses paramètres d’optimisation, de trouver ses « angles morts cognitifs ».
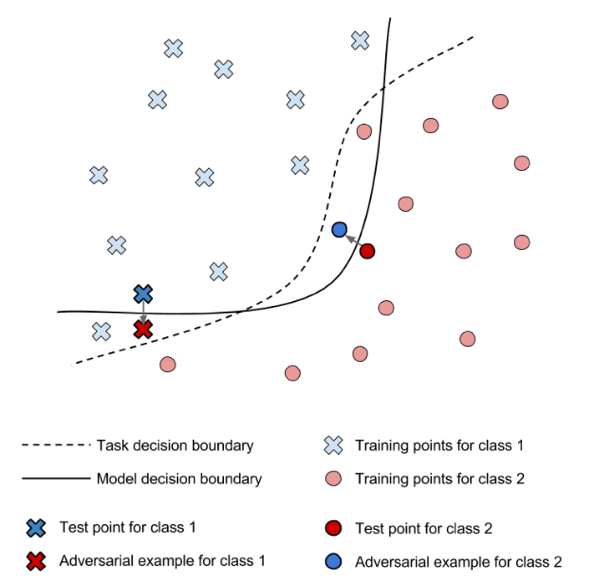
L’image ci-haut montre les frontières de l’humain et de l’algorithme.
En entraînant le modèle statistique avec les données des points plus pâles, l’algorithme décide de la frontière en trait plein pour catégoriser les futurs exemples qui lui seront fournis lors de sa phase opérationnelle.
Par contre, la réelle frontière pour la tâche est celle représentée en trait pointillé. Cette frontière réelle n’est habituellement connue qu’a posteriori ou grâce à l’intuition humaine. Il n’est donc pas possible de directement la programmer.
Ainsi, en perturbant légèrement un exemple préalablement correctement classé, il est possible qu’il devienne en dessous du critère du modèle, tout en restant au-dessus de la frontière réelle. Il en résulte une mauvaise classification par l’algorithme.
Le critère de décision de l’algorithme ne chevauche pas parfaitement le critère réel utilisé pas un être humain. Il est donc possible de trouver des exemples qui ne sont pas catégorisés de façon identique par un humain et un ordinateur.
Les causes fondamentales des Adversarial examples
Les causes plus fondamentales ne font cependant toujours pas l’objet d’un consensus dans la communauté scientifique. Certains arguments prônent que la grande complexité, la non-linéarité et le « overfitting » des modèles d’apprentissages profonds entraînent ce phénomène.
D’autres ont mis de l’avant qu’au contraire, la linéarité locale des frontières de décision est ce qui entraîne les exemples contradictoires.
De manière encore plus étrange, les exemples contradictoires créés pour un modèle en particulier sont habituellement transférables à un autre modèle! Cette propriété de transférabilité semble donc indiquer une généralisation à travers les différentes architectures d’apprentissage.
C’est également en exploitant cette propriété qu’il est possible de performer des attaques de types boîte noire :
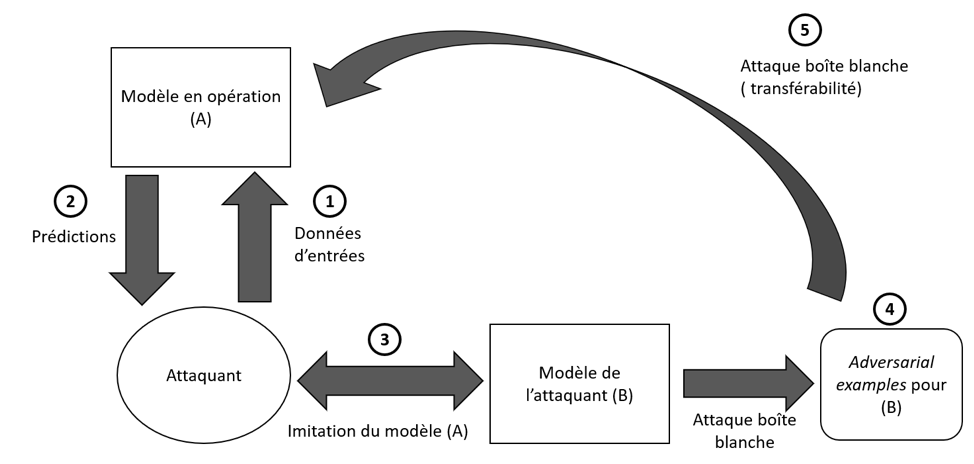
- On fournit des données au modèle (A) que l’on désire attaquer
- On observe les prédictions en sortie du modèle (A).
- On entraîne un modèle (B) pour imiter le plus fidèlement possible les prédictions du modèle (A)
- On crée des adversarial examples pour le modèle (B) en connaissant tous ses rouages internes (méthode boîte blanche)
- On soumet le modèle (B) aux adversarial examples créés pour le modèle (A). Grâce à la propriété de transférabilité, (A) classera faussement les adversarial example qui ont été créés pour (B). Une attaque de type boîte noire vient d’être faite.
Évidemment, il reste encore certains mystères à résoudre en ce qui a trait aux causes fondamentales des adversarial examples, comme ce champ d’études est relativement nouveau!
Comment mesurer la sensibilité et la robustesse d’un algorithme aux adversarial examples?
Maintenant que nous sommes conscients des impacts dévastateurs que peuvent avoir les adversarial examples, il est tout à fait normal de se demander :
Mes algorithmes sont-ils robustes à ces attaques? Et s’ils ne le sont pas, comment pourraient-ils le devenir?
Sensibilité du modèle au bruit
Une manière simple et efficace de valider la robustesse d’un algorithme face aux adversarial examples est de déterminer le bruit minimal qui entraîne systématiquement une mauvaise classification.
En augmentant graduellement le bruit introduit volontairement dans les données, il est possible d’observer en temps réel l’impact sur la précision de l’algorithme.
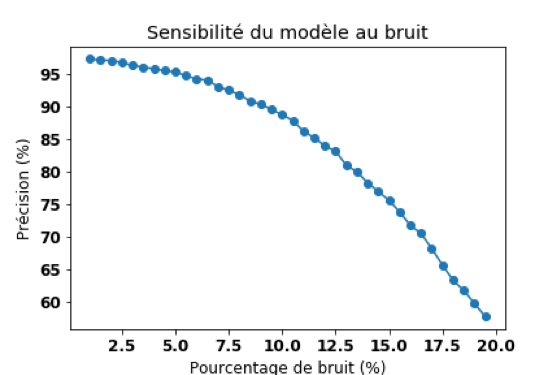
Le modèle testé classifie des images manuscrites de nombres entre 0 et 9. Il a été entraîné avec la base de données du MNIST et possédait une précision initiale de 97,5%.
Après l’introduction de seulement 15% de bruit au sein de chaque image, la précision est descendue à 75,6%.
Puisque les adversarial examples sont habituellement transférables d’un modèle à l’autre, il est intéressant de comparer les courbes de sensibilités pour des modèles de différentes complexités.
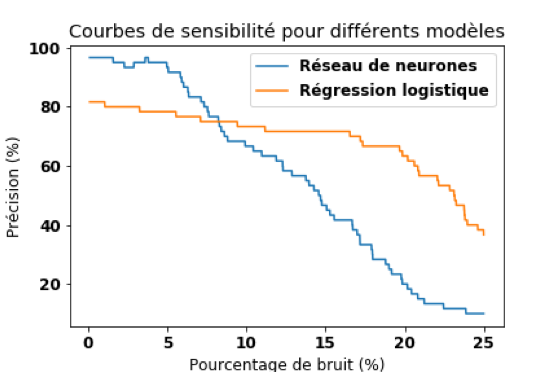
Le modèle testé classifie des données tabulaires représentant les longueurs et largeurs de pétales de fleurs. Les catégories sont différentes espèces de fleurs.
Sans bruit contradictoire, le réseau de neurones possède une précision de 96,7% alors que la régression logistique a une précision de 88,3%. Les deux modèles ont dû catégoriser les mêmes adversarial examples. Jusqu’à 15% de bruit, la précision de la régression logistique ne diminue que très peu.
En revanche, le réseau de neurones est beaucoup plus sensible (et donc moins robuste) au bruit. À 8% de perturbation, la précision de la régression devient meilleure que celle du réseau de neurones, grâce à sa meilleure robustesse face au bruit contradictoire!
As-tu essayé une simple régression?
Un scientifique de données et fin renard
L’expression « As-tu essayé une simple régression? » n’a jamais eu autant de sens! Les modèles très complexes tendent à être plus sensibles au bruit contradictoire. Parfois, il est désavantageux de complexifier inutilement les modèles.
À ce point-ci, le choix du modèle devient une décision d’affaires : désirez-vous avoir un modèle très précis, mais peu robuste au bruit contradictoire, ou un modèle un peu moins précis, mais qui résistera mieux au bruit contradictoire?
Heureusement, il existe différentes techniques permettant à vos modèles de devenir plus robustes. Par exemple, il est possible de générer des adversarial examples et de réentrainer l’algorithme sur ces nouvelles données.
En fournissant la « vraie catégorie désirée » des adversarial example à l’algorithme, il réussit à se réajuster et à devenir meilleur pour catégoriser ce type de données.
Ce n’est que le début
L’exploration des adversarial examples est actuellement un domaine de recherche très en vogue. De nouvelles attaques se développent, ainsi que les manières dont on peut s’en protéger.
La plupart des résultats sont intégralement disponibles en ligne pour permettre à tous de développer des algorithmes et des modèles plus robustes.
L’importance de la sécurité des algorithmes ne sera que croissante dans les prochaines années. Des régulations/normes à satisfaire pour mettre en opération des outils d’IA sont à notre porte.
Ne soyez pas pris au dépourvu et commencez dès maintenant à vous y préparer!
Informations supplémentaires et liens intéressants
Ah! Vous êtes encore là. J’en profite pour vous suggérer quelques liens intéressants pour en apprendre plus sur le sujet (comme vous êtes visiblement les plus curieux de nos lecteurs 👏) :
- La première publication scientifique à propos des adversarial examples qui a parti le bal.
- Quelques librairies et boîtes à outils en Python pour créer des adversarial examples sur vos propres modèles. :
- ART, de IBM (Adversarial-Robustness-Toolbox)
- Foolbox
- Cleverhans
- Machine Duping 101, Pwning Deep Learning Systems : Présentation à DEF CON 2016 (conférence sur la cybersécurité) à propos des adversarial examples.
- Pour lire plus en détail à propos d’image GoogLeNet
- Pour utiliser vous-même GoogLeNet à travers Keras
- Lignes directrices du gouvernement du Canada à propos d’un usage responsable de l’IA.
- Pour les nostalgiques de Picsou.

Guillaume est cofondateur de Moov AI et expert en marketing numérique.
Directeur marketing pour Urban Turtle (Pyxis Technologies) et Sharegate (GSoft), il a participé à la gestion des stratégies pour des produits ayant un fort succès commercial.





