

The most asked question I get from CTO’s is, “Can you please get out of my office, I told you, you don’t even work here!”
The second most asked question I get asked from CTO’s is, “Is our data good?” That’s it. The worlds most complicated 4 word question known to man. A mere whisper of this phrase can cause the ground to shake under the feet of a whole data team.
The data scientist looks to the data engineer and they both nod in silent agreement. “It is time” they say in unison. As they join hands they embark on the impossible journey to explain to a businessman what it means to have “good data”.
In this article I will explore what it means for a business to have “good data”, that is, data that can be used to drive key business decision making.
Don’t Insult My Data Quality. But Give It to Me Straight
The first thing to do when assessing data quality is to come up with a rubric or a scorecard that can be used to consistently evaluate data against certain criteria. In a next article, I will go into how exactly we can go about gathering these metrics from a technical standpoint.
For now we will continue our quest from a higher level view of our data. Below is an example of what your scorecard might consist of. Please keep in mind that data quality assessments starts with a granular view of your data.
For example, “The users first name field is currently 83% blank” , and end with “Before 2013 our data is essentially useless but after June 2015, when we changed our data gathering processes, we now have useable data. The data is clear, we need more help gathering data”.
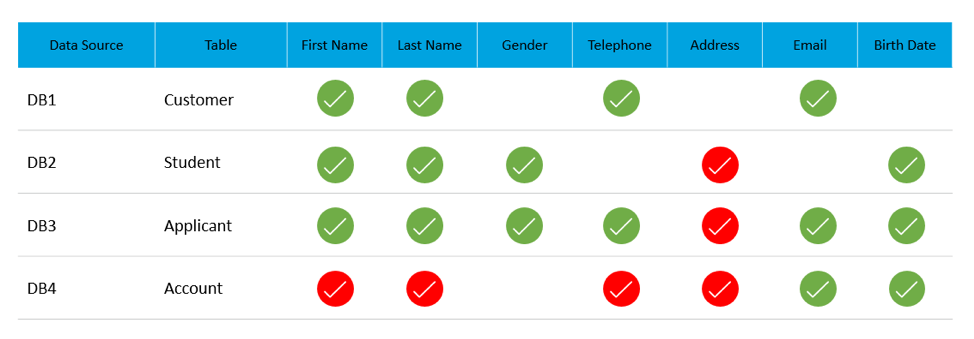
Starting with our very low level view of our data, we will go a head and fill in our scorecard to the best of our abilities. Ideally this would be done in a strictly mathematical and programmatically sound process. (Using an open source repository maybe?) This ensures that it is completely unbiased and a more scientifically sound procedure.
The green and red symbols used in the table above are an attractive goal. It summarizes an entire field in a binary fashion as good data or bad data. In reality, (I am sorry, I can hear your sighs from over the internet) the scorecard would most likely be replicated across multiple data quality standards.
Below are several standards that are commonly used in measuring data quality.

In the table, columns D-H are what are called metrics. Simply a way to measure data quality. Column D for example might count how many rows contain ‘null’ values are in the First_Name field in the Person table which is in the System1 database.
- Column E: Number of empty rows that have no value in a particular field.
- Column F: How many unique values have been found in a particular field.
- Column G: How many total rows there are for a particular field.
- Column H: The fill grade (very useful!) for a particular field
Where fill grade is calculated by:

If we think about it, data could be good in one way and bad in another. For example, if we are trying to do predictive analytics without a measurement of time the data would be considered ‘bad’.
The same data set might prove to be incredibly useful in determining the popularity of one product versus another.
But I Only Have a Small Amount of Data to Work With
This ladies and gentlemen, is the most common insecurity when it comes to having confidence in the outcome of a datasets resulting recommendation. Data engineers and Data scientists suffer deeply from this short coming so please, be compassionate.
The most relevant (and cringeworthy) adage we could come up with was: “It’s not the size that counts, its how you use it”. -Sorry. The good news is that small amounts of data are often a misconception of what it means to have enough data to work with.
Just because you don’t have Big Data doesn’t mean you don’t have useful data.
Stop me if you’ve heard of any of these before: Blockchain, Bitcoin, Internet of Things, Quantum Computing, Robotic Process Automation, etc… Buzzwords like Big Data have been floating around the industry for almost 15 years! It is no wonder we feel insecure with our Gigabytes or Terabytes when the Google distributed file system was conceptualized in 2003 in order to handle Petabytes of data.

An extremely pervasive belief is that if you don’t have Big Data, you cannot derive any useful insights from your data set. Here is where we tell you a little secret. It is plausible to run predictive AI algorithms on Megabytes worth of data.
I’ll let that sink in for a second.
Proof of concept projects run internally (and externally by others) have returned confidence results that score in the 85%-100% range, which is a whole lot better than flipping a coin. (How we make our hiring decisions) Although, we must add the fact that there is a lower threshold on how much data can drive valuable insights.
If you are working with hundreds of rows (or sometimes even thousands) it would probably be advisable to not base any critical decisions upon it.
Data Quality
This is the first step on determining data quality. I understand it seems like a long process and… that’s because it is. The importance of determining if data is useable or not cannot be understated. (It’s in bold!? It must be important, let me re-read that sentence.)
If your decision plan is to optimize operational cost and is based on erroneous data you could very well be leading your company straight to its avoidable demise. So please, consider potentially hiring a professional if your technical skills are a tad rusty or if you like sleeping at night. (or professionals depending on your data complexity, number of source systems, amount of raw data and the severity of the decision’s potential business impact.)
If you are slightly more technical or will be assessing your data quality yourself (first consider a data professional), the next article (published soon) will go into the nitty gritty on how to actually go about building the data scorecard with a little bit of programming.

Guillaume is co-founder and VP Marketing of Moov AI. A natural communicator, he is dedicated to promoting the brand and growing the company. He prides himself on forging solid partnerships and developing strategies to ensure optimal strategic positioning for Moov AI. As a speaker, Guillaume enjoys awakening audiences to the transformative influence of AI in business ecosystems. He has extensive marketing expertise in different industries, having held the position of Marketing Director at GSoft (Workleap) and Pyxis Technologies.





