
This guide will provide you with all the information that you need to understand what is OCR, what are its advantage and how to make the most out of this technology in a business context.
What is Optical Character Recognition (OCR)?
Optical Character Recognition (OCR) is an electronic conversion of the typed, handwritten or printed text images into machine-encoded text.
With OCR a huge number of paper-based documents, across multiple languages and formats can be digitized into machine-readable text that not only makes storage easier but also makes previously inaccessible data available to anyone at a click.
Just think about the amount of archive boxes full of paper that lies in a city or a government basement.
Such images and documents can be scanned as a document, a document photo, or a scene photo (e.g. text on signs and billboards).
How Does OCR Work?
Different fonts and ways to write a single character make this issue a challenge to solve. Before selecting an OCR algorithm, the image must be preprocessed for the image to be ready to be “read”.
Pre-processing
OCR software often “pre-process” images to boost the chances of recognition.
Techniques include:
1. De-skew
If the document was not correctly aligned when scanned, it may need to be tilted a few degrees clockwise or counterclockwise to create text lines completely horizontal or vertical.
2. Despeckle
Remove positive and negative spots, smoothing edges
3. Binarization
Convert an image to black-and-white (called a “binary image” because there are two colors). The binarization task is conducted as an easy and accurate way to distinguish text (or any other required image element) from the background.
4. Line removal
Cleans up non-glyph boxes and lines.
5. Layout analysis or “zoning”
Identifies columns, paragraphs, captions, etc., as blocks. Particularly useful in multi-column layouts and tables.
6. Line and word detection
Establish word and character shapes baseline, divides words when required.
7. Script recognition
In multiple language documents, the script may transform at the word level and therefore script identification is vital before the relevant OCR can be utilized to manage the particular script.
8. Character isolation or “segmentation”
For OCR characters, various characters linked by image artifacts should be divided, single characters broken into several artifact-based pieces should be linked.
9. Normalization
Normalize aspect ratio and scale.
Feature Extraction
There are two main methods for extracting features in OCR:
- In the first method, the algorithm for feature detection defines a character by evaluating its lines and strokes.
- In the second method, pattern recognition works by identifying the entire character.
We can recognize a line of text by searching for white pixel rows that have black pixels in between. Similarly, we can recognize where a character starts and finishes.
The following pictures show the visualization of these methods respectively:
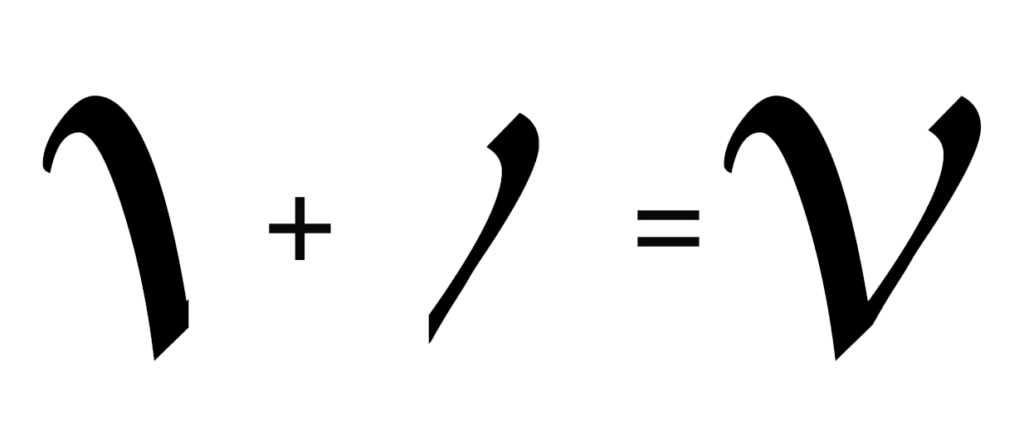


Next, we convert the image of the character into a binary matrix where white pixels are 0s and black pixels are 1s as shown in the following image:

Then, by using the distance formula, we can find the distance from the center of the matrix to the farthest 1.
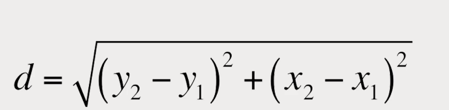
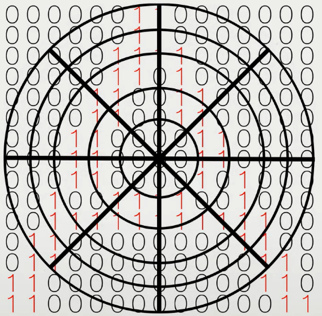
We then create a circle of that radius and split it up into more granular sections.
At this stage, the algorithm compares each subsection to a database of matrices representing characters with different fonts to identify the character it has most in common statistically.
It makes it easy to bring printed media into the digital world by doing this for every line and character.
Post-processing
OCR accuracy can be improved if the output is limited by a lexicon (a list of words permitted in a document). For instance, this could be all the words in English, or a more technical lexicon for a particular field.
This method can be less efficient if the document contains words that are not in the lexicon, like proper nouns.
Fortunately, to improve accuracy, there are OCR libraries available online for free. The Tesseract library is using its dictionary to control the segmentation of characters.
The output stream can be a single string or a character file, but more advanced OCR systems retain the original page structure and, for example, create a PDF containing both the original image pages and a searchable textual image.
Error correction
The “near neighbor analysis” can use frequencies for co-occurrence to correct mistakes, by noting that some words have been seen together. For instance, “Washington, D.C.” is more prevalent in English than “Washington DOC.”
Grammar
The grammar can also help to determine the language being scanned, for instance, a word is likely to be a verb or noun, provides higher accuracy.
In OCR post-processing, the Levenshtein Distance algorithm is often used to further maximize OCR API outcomes.
Use cases of OCR
OCR engines have been developed into a range of domain-specific OCR applications including receipt, invoice, check and the legal document.
More instances of use can be discovered as follows:
- Data entry for business documents, e.g. checks, passports, invoices, bank statements, and receipts.
- Automatic recognition of license plate
- In airports, passport recognition and information extraction
- Automatic insurance document key information extraction
- Extracting business card information into a contact list
- Make numeric versions of huge printed document, e.g. book scanning
- Make electronic images of printed documents searchable, e.g. Google Books
- Converting handwriting in real-time to control a computer (pen computing)
OCR Use Case by Industry
Banking
The banking industry is a significant consumer of OCR along with other economic sectors such as insurance and securities.
The most common use of OCR is to properly manage cheques:
- The handwritten cheque is scanned
- Its details are transformed into digital text
- The signature is validated
- The check is cleared in real-time
All without human involvement.
Although printing cheques have almost 100% accuracy (only the signature verification requires matching a pre-existing database), full autonomy for handwritten controls remains a long way to go.
However, with deep learning AI methods applied to OCR handwriting, it may not be as unsolvable as it might seem.
A decreased cheque clearance processing time is a financial advantage for everyone, from payer to bank to payee.

Legal
Few industries generate as much paperwork as the legal industry, and so OCR has multiple applications herein.
Digitalization, storage, database and searching with the simplest OCR readers is possible in all printed documents: affidavits, judgments, filings, statements, wills, etc.
This technique is also available for records in Chinese, Arabic and other scripts, with OCR technology expanding to languages that do not use the Roman script.
Fast access to legal documents from millions of past cases certainly has an advantage for an industry that relies heavily on the past.
Healthcare
Another industry that works well with OCR is healthcare. The entire medical history can be scanned and stored on a computer: reports, X-rays, previous diseases, treatments or diagnostics, tests, hospital records, insurance payments, etc. All of those are made accessible in a single place, and searchable.
The fact that the whole hospital record is digitally stored also represents a major advantage for epidemiology and also for logistics (maintaining of appropriate drug stores, equipment, and other consumer products).
Such records sum up in several hospitals across a region that provides an enormous database for health policy, legislation, and provision on a basis of data.

Supply Chain
In the food, drinking, pharmaceutical and cosmetics industries, quality control through every stage of the process is critical in complying with the laws of safety and anti-counterfeiting.
Items must be located within the supply chain at any specified moment, with clear information documentation of their origin and location.
While product tracking is often considered a barcoding application, OCR allows you to read lot codes, batch codes, expiry dates, and serial numbers to follow a product at all stages of the packing cycle – from the package labeling to board packaging to palletizing operation.
You can program an OCR application for comparing the current text with the expected string, as defined in the database, and flag missing or out of sequence serial numbers.
Barcodes and OCR are often used together to maximize information collection accuracy.

Benefits of OCR
Searchability
You can save your scanned file in the form of .doc,.rtf,.txt (simplest), pdf, etc. after you have converted your scanned file into readable text. These files can then be easily searched using almost any system.
Editability
You may want to modify an old contract you have written years ago or revise an old will. After digitization of your document using OCR, you can easily edit it with a word processor instead of typing the entire document.
Accessibility
Once an OCR scanned document is made accessible on a common database, it is accessible to anyone with access to that database. This is especially useful for banks who can check a customer’s previous credit history anytime and anywhere.
Another use could be to make government archives available so that the land and property ownership record or the birth certificate of your grandfather can be found instantly from anywhere.
Storability
Digitalization reduces the space required for storage from an entire room (if not “rooms”) to bytes on a server to allow more productivity. Also, the (now) useless paper archive can now be recycled.
Backups
Instead of keeping expensive paper duplicates and triplicates in paper-form, digital backups can be made cheaply and possibly unlimitedly.
In addition, OCR offers much more sustainability in documentation management.
Translatability
Modern OCR can manage a large number of languages, from Arabic to Indian to Chinese. This implies that a paper, in one language, can be searched, digitized and translated in any other language.
This work is simplified using the Unicode Standard and computer translation program based on machine learning (for example, Google Translate).
Therefore, we can almost eliminate the need for professional translators.
How will OCR help your business?
OCR has several advantages as a move towards digitalization. In business, there is often a very high volume of data and documents, whether on contracts, shipping slips, government forms, licenses, certificates, tariff sheets, catalogs, etc.
After digitizing you can compare them with several other digital documents, so you can get the best prices, services, terms and conditions, etc. easily by comparing documents.
By using OCR, you can check for variances from the original terms and conditions with your signed contract. Cheques can likewise be verified for the right quantity, invoices compared, etc.
Also, by digitalizing documents, you make them accessible for a most advanced analysis, which can inform you about long term improvements in your business. You can detect loss leaders, tax avoidance or overpayment and much more, which allows a considerable saving in price.
These are truly the advantages to digitalization, but OCR is a critical first phase in analog records transformation.
If you want to know more about OCR, here is a list of reference and interesting documents about it:

Guillaume is co-founder and VP Marketing of Moov AI. A natural communicator, he is dedicated to promoting the brand and growing the company. He prides himself on forging solid partnerships and developing strategies to ensure optimal strategic positioning for Moov AI. As a speaker, Guillaume enjoys awakening audiences to the transformative influence of AI in business ecosystems. He has extensive marketing expertise in different industries, having held the position of Marketing Director at GSoft (Workleap) and Pyxis Technologies.





